
TLDR: This research piece provides an overview of parallel design architectures for blockchains, using three relevant examples: Solana, Sei, and Monad. It highlights the differences between optimistic and deterministic parallelization and examines the nuances of state and memory access across these chains.
Introduction
In 1837, computer scientist and mathematician Charles Babbage designed the “Analytical Engine,” which laid the theoretical foundation for parallel computation. Today, parallelization is a pivotal theme within the crypto world as blockchains attempt to push the boundaries of processing, efficiency, and throughput.

Parallel computation enables many calculations or processes to be executed simultaneously, as opposed to calculations executing serially or one after the other. Parallel computing refers to breaking down larger problems into smaller, independent parts that can be executed by multiple processors communicating via shared memory. Parallel systems have a number of advantages, such as increased efficiency and speed, scalability, improved reliability and fault tolerance, better resource utilization, and the ability to handle very large data sets.
However, it’s crucial to recognize that the effectiveness of parallelization depends on the specifics of the underlying architecture and implementation. Two core bottlenecks to blockchains are cryptographic functions (hash functions, signatures, elliptical curves, etc.) and memory/state access. With blockchains, one of the key components of designing an efficient parallel system lies in the nuances of accessing state. State access refers to a transaction’s ability to read and write to a blockchain’s state, including storage, smart contracts, and account balances. For a parallelized blockchain to be effective and performant, state access must be optimized.
There are currently two schools of thought on optimizing state access for parallelized blockchains: deterministic parallelization vs. optimistic parallelization. Deterministic parallelization requires code to explicitly declare upfront which parts of the blockchain state will be accessed and modified. This allows a system to determine which transactions can be processed in parallel without conflicts beforehand. Deterministic parallelization allows for predictability and efficiency (especially when transactions are mostly independent). However, it does create more complexity for developers.
Optimistic parallelization does not require code to declare its state access upfront and processes transactions in parallel as if there will be no conflicts. If a conflict does arise, optimistic parallelization will either re-run, reprocess, or run the conflicting transactions serially. While optimistic parallelization allows more flexibility for developers, re-execution is required for conflicts, resulting in this method being most efficient when transactions are not in conflict. There is no right answer as to which of these approaches is better. They are simply two different (and viable) approaches to parallelization.
In Part I of this series, we will first explore some basics of non-crypto parallel systems, followed by the design space for parallel execution for blockchains, focusing on three core areas:
- Overview of Crypto Parallel Systems
- Approaches to Memory & State Access
- Parallel Design Opportunities
Non-Crypto Parallel Systems
Taking what we have just read above about what parallel computation enables and the advantages of parallel systems, it is easy to understand why the adoption of parallel computation has taken off in recent years. Increased adoption of parallel computing has enabled many breakthroughs in the last several decades alone.
- Medical Imaging: Parallel processing has fundamentally transformed medical imaging, leading to significant increases in speed and resolution across various modalities such as MRI, CT, X-rays, and optical tomography. Nvidia is at the forefront of these advancements, providing radiologists with enhanced artificial intelligence capabilities through its parallel processing toolkit, which enables imaging systems to handle increased data and computational loads more effectively.
- Astronomy: Some new phenomena, such as understanding black holes, have only been made possible using parallel supercomputers.
- Unity’s Game Engine: Unity’s engine uses the capabilities of GPUs–which are built for massive graphical workloads–to help with performance and speed. The engine is equipped with multithreaded and parallel processing features, yielding a seamless gaming experience and creating complex, detailed gaming environments.
Let’s examine three blockchains that have implemented parallel execution environments. First, we will unpack Solana, followed by two EVM-based chains, Monad and Sei.
Parallel Design Overview – Solana
At a high level, Solana’s design philosophy is that blockchain innovation should evolve with hardware advancements. As hardware improves over time via Moore’s Law, Solana is designed to benefit from increased performance and scalability. Solana Co-Founder Anatoly Yakovenko initially designed Solana’s parallelization architecture more than five years ago, and today, parallelism as a blockchain design principle is spreading rapidly.
Solana uses deterministic parallelization, which comes from Anatoly’s past experience working with embedded systems, where you typically declare all state upfront. This enables the CPU to know all the dependencies, which enables it to pre-fetch the necessary parts of memory. The result is optimized system execution, but again, it requires developers to do extra work upfront. On Solana, all memory dependencies for a program are required and stated in the constructed transaction (i.e., Access Lists), enabling the runtime to schedule and execute multiple transactions in parallel efficiently.
The next major component of Solana’s architecture is the Sealevel VM, which is Solana’s parallel smart contract runtime. Sealevel natively supports processing multiple contracts and transactions in parallel based on the number of cores a validator has. A validator in a blockchain is a network participant responsible for verifying and validating transactions, proposing new blocks, and maintaining the integrity and security of the blockchain. Since transactions declare what accounts need to be read and write locked upfront, the Solana scheduler is able to determine which transactions can be executed concurrently. Because of this, when it comes to validation, the “Block Producer ” or Leader is able to sort thousands of pending transactions and schedule the non-overlapping transactions in parallel.
The final design element for Solana is “pipelining.” Pipelining occurs when data needs to be processed in a series of steps, and different hardware is responsible for each. The key idea here is to take data that needs to be run serially and parallelize it using pipelining. These pipelines can be run in parallel, and each pipeline stage can process different transaction batches.
These optimizations allow Sealevel to organize and execute independent transactions simultaneously, utilizing the hardware’s capability to process multiple data points at once with a single program. Sealevel sorts instructions by programID and executes the same instruction on all relevant accounts in parallel.
With these innovations in mind, we can see that Solana was intentionally designed to support parallelization.
Parallel Design Overview – Sei
Sei is a general-purpose, open-source Layer 1 blockchain specialized for the exchange of digital assets. Sei V2 leverages optimistic parallelization and, as a result, is more developer-friendly than its deterministic counterpart. In optimistic parallelization, smart contracts can be executed more seamlessly and concurrently without requiring developers to declare their resources upfront. This means that the chain optimistically runs all transactions in parallel. Still, when there are conflicts (i.e., multiple transactions accessing the same state), the blockchain will keep track of the specific storage component that each conflicting transaction impacts.
Sei’s blockchain approaches executing transactions using “Optimistic Concurrency Control (OCC).” Concurrent transaction processing occurs when multiple transactions are simultaneously alive in a system. There are two phases in this transaction approach: execution and validation.
In the execution phase, transactions are optimistically processed, with all reads/writes temporarily stored in a transaction-specific store. After this, every transaction will enter the validation phase, where the information in the temporary store operations is checked against any state changes made by previous transactions. If a transaction is independent, the transaction runs in parallel. If a transaction reads data modified by another transaction, this would create a conflict. Sei’s parallel system will identify each conflict by comparing the read sets of transactions versus the latest state changes in a multi-version store (these are indexed by transaction order). Sei will re-execute and re-validate instances where conflicts arise. This is an iterative process involving execution, validation, and re-running in order to fix the conflicts. The graphic below illustrates Sei’s approach to transactions when a conflict arises.
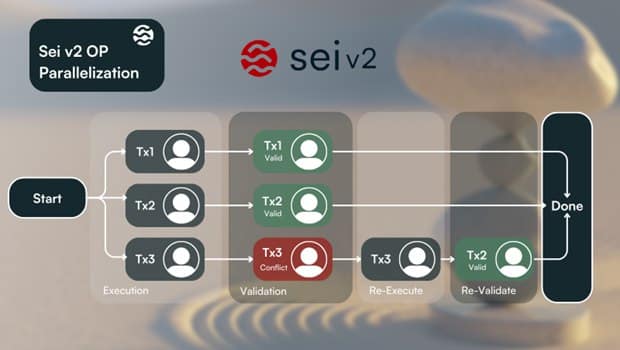
Sei’s implementation results in cheaper gas fees and a broader design space for EVM developers. Historically, EVM environments have been limited to <50 TPS, which forced developers to create applications that followed anti-patterns. Sei V2 enables developers to approach sectors that typically require high performance and low fees, like DeFi, DePIN, and Gaming.
Parallel Design Overview – Monad
Monad is building a parallel EVM Layer 1 with full bytecode compatibility. What makes Monad unique is not just its parallelization engine but what they’ve built under the hood to optimize it. Monad takes a unique approach to its overall design by incorporating several key features, including pipelining, asynchronous I/O, separating consensus and execution, and MonadDB.
A key innovation in Monad’s design is pipelining with a slight offset. The offset enables more processes to be parallelized by running multiple instances simultaneously. Therefore, pipelining is used to optimize a number of functions, like state access pipelining, transaction execution pipelining, pipelining within consensus and execution, and pipelining within the consensus mechanism itself.
Next, we will double-click into Monad’s parallelization piece. In Monad, transactions are linearly ordered within the block, but the goal is to reach this end state faster by leveraging parallel execution. Monad uses an optimistic parallelization algorithm for its execution engine design. Monad’s engine processes transactions simultaneously and then performs an analysis to ensure that the outcome would be identical if the transactions were executed one after another. If there are any conflicts, you need to re-execute. The parallel execution here is a relatively simple algorithm, but combining it with the other key innovations of Monad is what makes this approach novel. One thing to note here is that even if re-execution occurs, it is usually cheap because the inputs needed for an invalid transaction will almost always remain in the cache, so it will be a simple cache lookup. Re-execution is guaranteed to succeed because you have already executed the previous transactions in the block.
Monad also improves performance by separating execution and consensus, similar to Solana and Sei, in addition to deferred execution. The idea here is that if you relax the condition for execution to be completed by the time consensus is complete, you can run both in parallel, resulting in additional time for both. Of course, Monad uses a deterministic algorithm to handle this condition to ensure one of these doesn’t run too far ahead with no possibility of catching up.
Unique Approaches to State Access & Memory
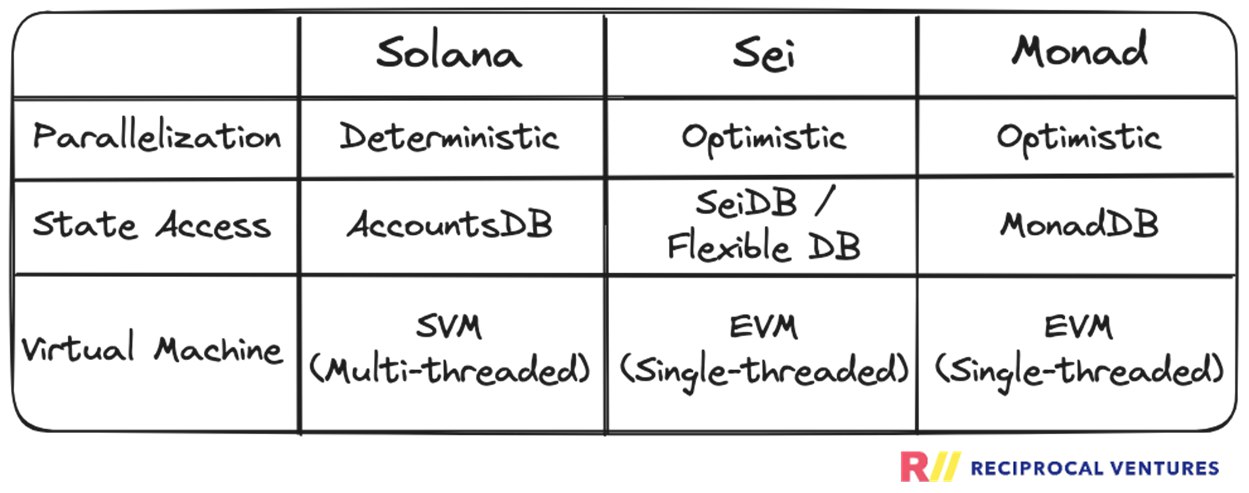
As I mentioned at the beginning of this post, state access is one of the typical performance bottlenecks for blockchains. The design choices around state access and memory can ultimately dictate whether a specific implementation of a parallel system will improve performance in practice. Here, we will unpack and compare the different approaches taken by Solana, Sei, and Monad.
Solana State Access: AccountsDB / Cloudbreak
Solana utilizes horizontal scaling to distribute and manage state data across multiple SSD devices. Many blockchains today use generic databases (i.e., LevelDB) with limitations on handling a large number of concurrent reads and writes of state data. To avoid this, Solana built its own custom accountsDB leveraging Cloudbreak.
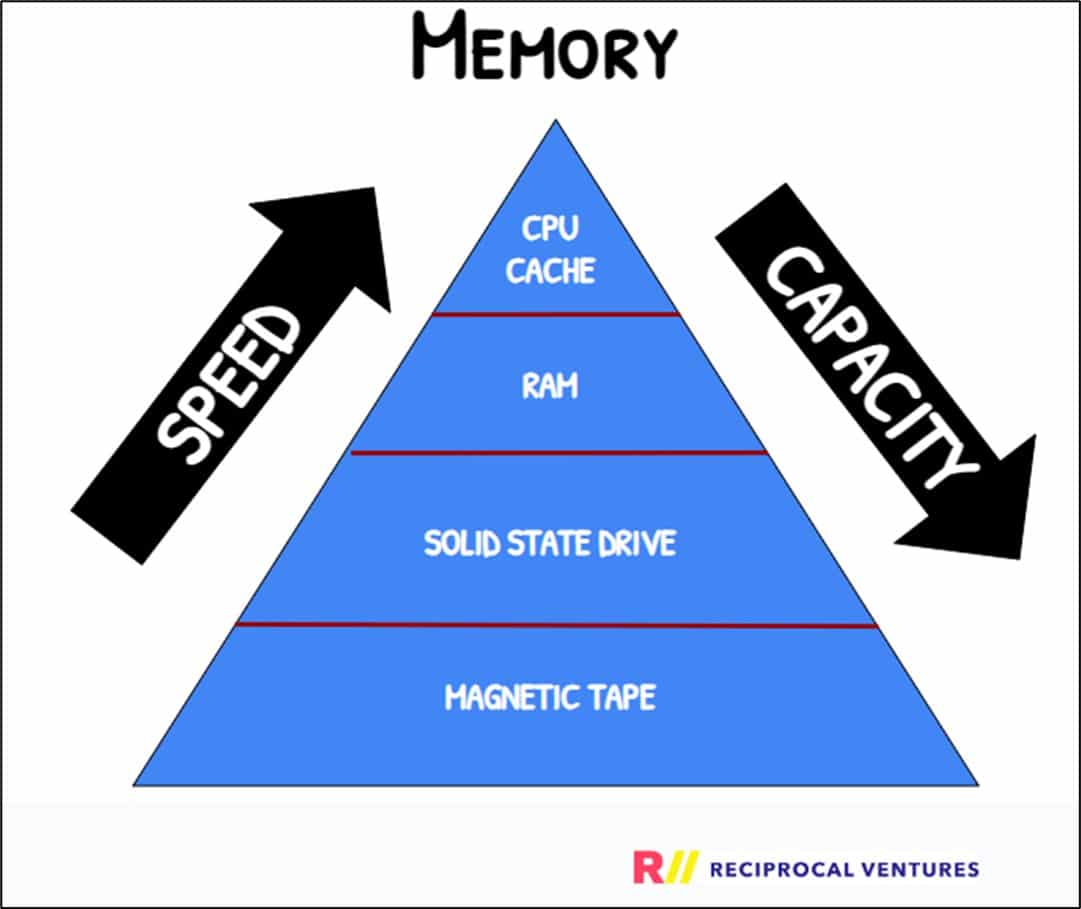
Cloudbreak is engineered for parallel access across I/O operations rather than relying solely on RAM, which is inherently fast. I/O operations (Input/Output) refers to reading data from or writing data to an external source, such as a disk, network, or peripheral device. Initially, Cloudbreak employed an in-RAM index for mapping public keys to accounts holding balances and data. However, as of writing this paper and version 1.9, the index has been moved out of RAM and onto SSDs. This shift allows Cloudbreak to simultaneously handle 32 (I/O) operations in its queue, enhancing throughput across multiple SSDs. Consequently, blockchain data such as accounts and transactions can be accessed efficiently, as if they were in RAM using memory-mapped files. The graphic below represents an illustrative memory hierarchy. Although RAM is faster, it has less capacity than SSD and is generally more expensive:
By scaling horizontally and distributing state data across multiple devices, Cloudbreak reduces latency and improves efficiency, decentralization, and network resilience within the Solana ecosystem.
Sei State Access: SeiDB
Sei has redesigned its storage, SeiDB, to address several issues: write amplification (how much metadata is needed to maintain data structures, smaller = better), state bloat, slow operations, and performance degradation over time. The new redesign is now broken into two components: state store and state commit. Recording and verifying any changes to data is handled by state commitment, while the database that keeps account of all the data at any point is handled by state storage (SS).
In Sei V2, the State Commitment uses a memory-mapped IAVL tree architecture (MemIAVL). The memory-mapped IAVL tree stores less metadata, which reduces state storage and state sync times and makes running a full node much easier. The memory-mapped IAVL tree is represented as three files on disk (kv, branch, leaves); therefore, less metadata needs to be tracked, which helps reduce state storage by over 50%. The new MemIAVL structure helps reduce the write amplification factor because it reduces the metadata needed to maintain data structures.
The updated SeiDB allows for flexible database backend support for the state storage layer. Sei believes that different node operators will have diverse requirements and storage needs. Therefore, the SS has been designed to accommodate different backends, providing operators with freedom and flexibility, i.e., PebbleDB, RocksDB, SQLite, etc.
State Access: MonadDB
There are some important nuances to Monad’s state access. First, most Ethereum clients leverage two types of databases: B-Tree databases (i.e., LMDB) or log-structured merge tree (LSM) databases (i.e., RocksDB, LevelDB). Both of these are generic data structures not explicitly designed for blockchains. Additionally, these databases don’t leverage the most up-to-date advancements in Linux technology, especially regarding asynchronous operations and I/O optimizations. Lastly, Ethereum itself manages the state using Patricia Merkle Trie, which specializes in cryptography, verification, and proofs. The main issue is that clients must integrate this specific Patricia Merkle Trie into more generic databases (i.e., B-Tree / LSM), with significant performance drawbacks such as excessive disk access.
All of the above helps set the stage for why Monad decided to create its custom-built MonadDB database, specifically designed to handle blockchain data and state access more efficiently. Some of the key features of MonadDB include a parallel access database, a custom database optimized for Merkle Trie Data, efficient state access over standard RAM usage, and decentralization and scalability.
MonadDB is explicitly designed for blockchains, making it more performant than leveraging generic databases. The custom MonadDB is specialized and tailored for efficiently managing Merkle trie-type data, enabling parallel access to multiple trie nodes at the same time. Though the cost of a single read on MonadDB versus some of the generic databases listed above is the same, the key property here is that MonadDB can run many reads in parallel, leading to a massive speedup.
MonadDB enables simultaneous state access to the parallel access database. Because Monad is building this database from scratch, it is able to leverage the most up-to-date Linux kernel technologies and the full power of SSDs for asynchronous I/O. With async I/O, if a transaction requires a reading state from disk, this shouldn’t stop operations waiting for completion. Instead, it should begin the read and simultaneously continue processing other transactions. This is how async I/O significantly speeds up processing for MonadDB. Monad is able to extract better performance from the hardware by optimizing SSD usage and reducing the reliance on excessive RAM. This has the additional benefit of aligning with decentralization and scalability.
Conclusion
In conclusion, exploring parallelization in blockchains through the lens of Solana, Sei, and Monad provides a comprehensive understanding of how different architectures and approaches can enhance performance and scalability. Solana’s deterministic parallelization, with its emphasis on declaring state access upfront, offers predictability and efficiency, making it a powerful choice for applications requiring high throughput. On the other hand, Sei’s optimistic parallelization approach prioritizes developer flexibility and is well-suited for environments where transaction conflicts are infrequent. With its unique blend of optimistic parallelization and custom-built MonadDB, Monad presents an innovative solution that leverages the latest technological advancements to optimize state access and performance.
Each blockchain presents a distinct approach to addressing the challenges of parallelization, with its own set of trade-offs. Solana’s design is geared towards maximizing hardware utilization and throughput, while Sei focuses on easing the development process, and Monad emphasizes a tailor-made database solution for blockchain data. These differences highlight the diversity in the blockchain ecosystem and the importance of choosing the right platform based on the application’s specific needs.
As the blockchain space continues to evolve, the advancements in parallelization techniques demonstrated by Solana, Monad, and Sei will undoubtedly inspire further innovation. The journey towards more efficient, scalable, and developer-friendly blockchains is ongoing, and the lessons learned from these platforms will play a crucial role in shaping the future of blockchain technology.
In Part II of this series, we’ll dive into the economic implications and tradeoffs associated with these parallel design systems.
Tweet
Ali Sheikh
Principal
Ali has been in Crypto since 2015. A crypto enthusiast at heart, Ali has been part of Defi Summer, Solana Summer, NFTs, Yield Farming, DAOs and much more. As part of Reciprocal’s interest in cryptocurrency, Ali is actively investing in people working on Web3 Applications, Decentralized Finance, and Infrastructure.
Prior to joining Reciprocal, Ali was a software engineer at Flexport where he also focused on marketplace and analytics. Before this, he spent time on the venture investment team at Cisco covering the Internet of Things. He also spent time in the mobile gaming industry leading User Acquisition and Growth. Ali started his career at Morgan Stanley in the investment banking division.
Ali received his B.A. in Economics from the University of Chicago and is currently pursuing a master’s in computer science from the University of Pennsylvania.
When he is not spending time in crypto, Ali can be found on hike paths, boxing, or exploring nature with his young daughter.

